 |
FREYA WP2 User Story 5 | As a student using the British Library's EThOS database, I want to be able to find all dissertations on a given topic. |
|---|---|---|
It is important for postgraduate students to identify easily existing dissertations on a research topic of interest.
This notebook uses the DataCite GraphQL API to retrieve all dissertations for three different queries: Shakespeare, Machine learning and Ebola. These queries illustrate trends in the number of dissertations created over time.Goal: By the end of this notebook you should be able to:
- Retrieve all dissertations (across multiple repositories) matching a specific query;
- For each query:
- Display a bar plot of the number of dissertations per year, including a trend line, e.g.
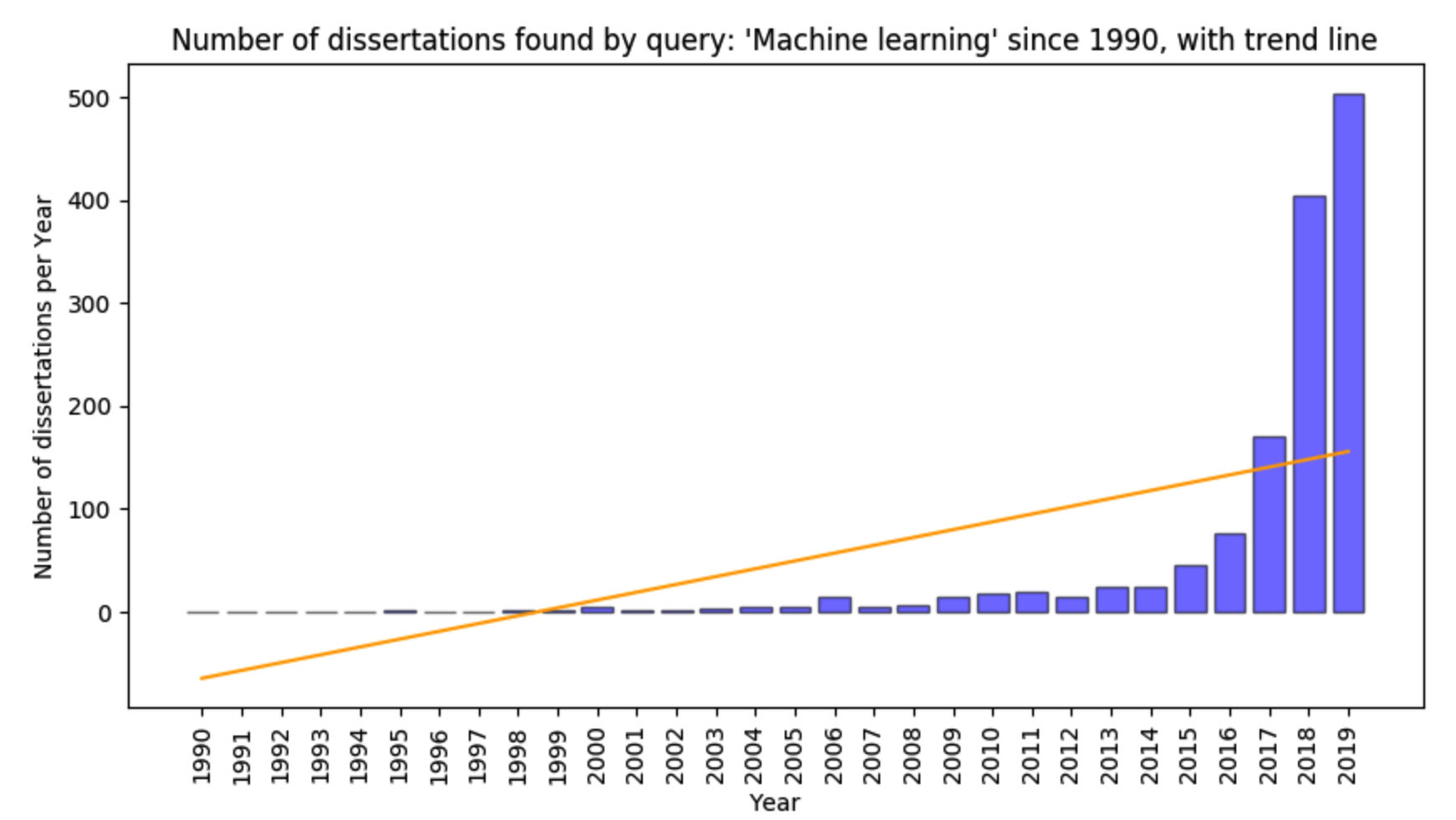
- Display a pie chart showing the number of dissertations per repository;
- Display a word cloud of words from dissertation titles and descriptions, e.g.
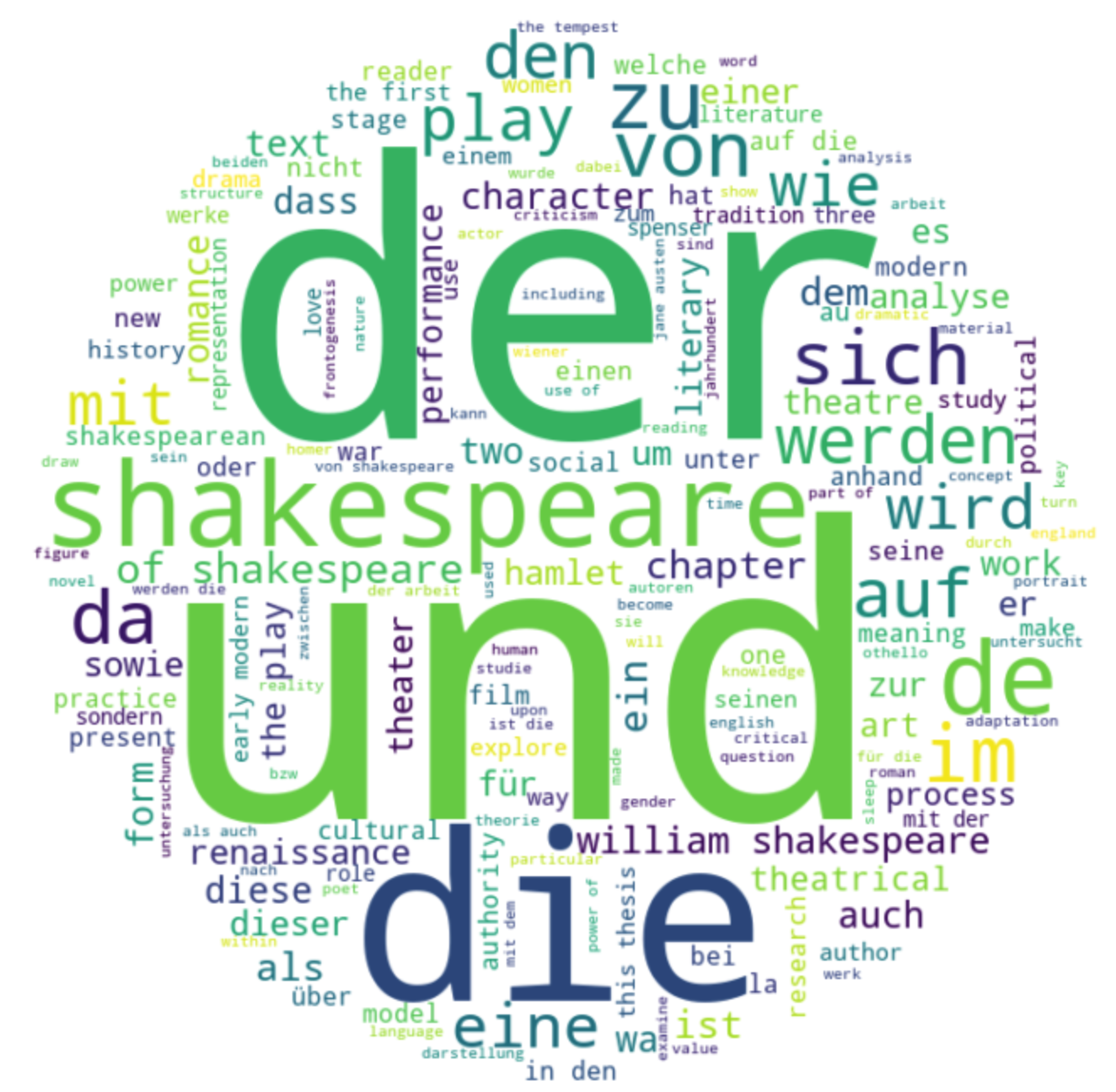
- Download all dissertations in a single BibTeX file.
- Display a bar plot of the number of dissertations per year, including a trend line, e.g.








