 |
FREYA WP2 User Story 10 | As a funder, we want to be able to find all the outputs related to our awarded grants, including block grants such as doctoral training grants, for management info and looking at impact. |
|---|---|---|
Funders are interested in monitoring the output of grants they award - while the grant is active as well as retrospectively. The quality, quantity and types of the grant's outputs are useful proxies for the value obtained as a result of the funder's investment.
This notebook uses the DataCite GraphQL API to retrieve all outputs of FREYA grant award from European Union to date.Goal: By the end of this notebook you should be able to:
- Retrieve all outputs of a grant award from a specific funder;
- Plot number of outputs per year-quarter of the grant award duration;
- Display de-duplicated outputs in tabular format, including the number of their citations, views and downloads;
- Plot a pie chart of the number of outputs per resource type;
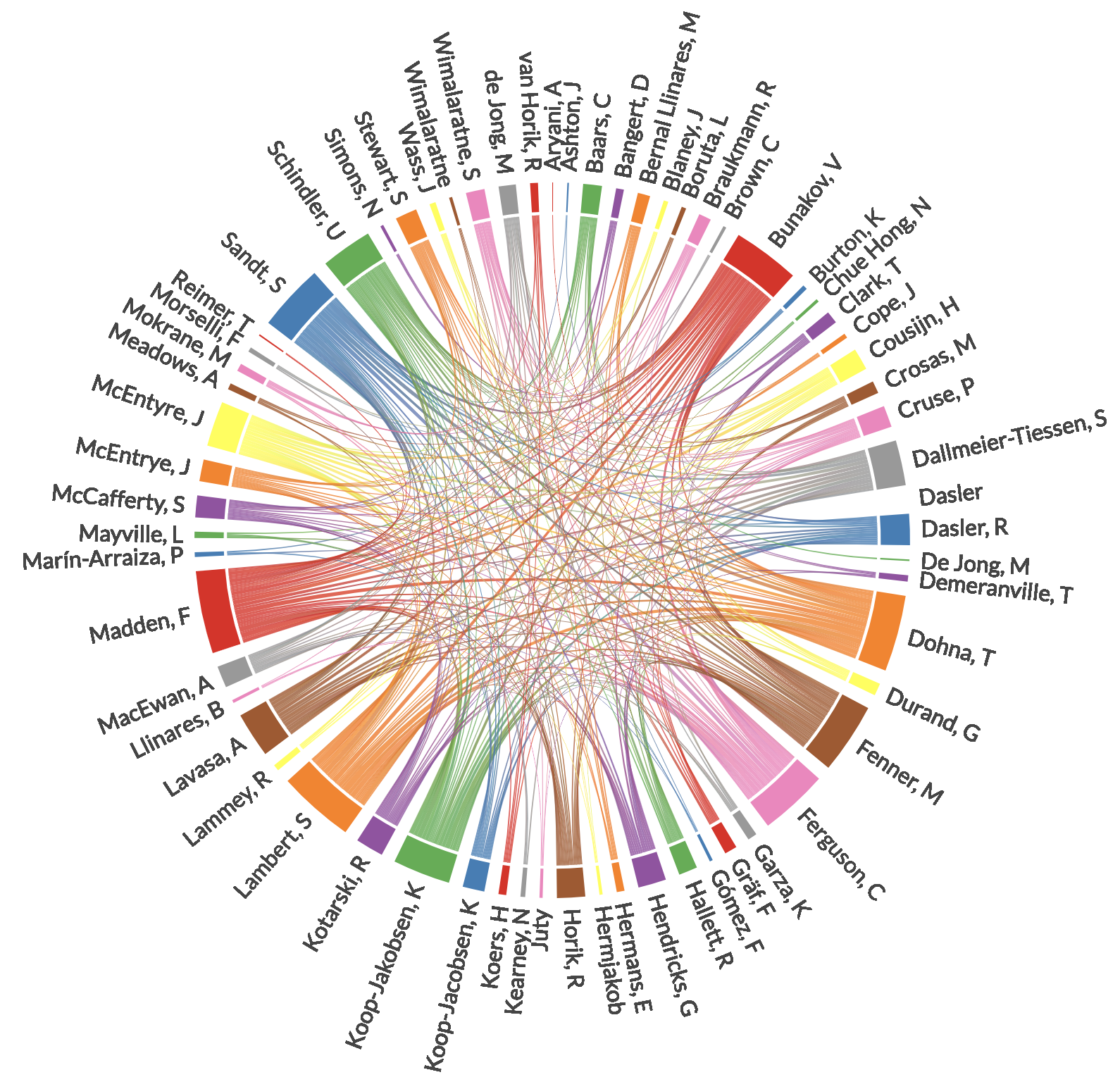
- Display an interactive chord plot of co-authorship relationships across all outputs, e.g.
- Plot a pie chart of the number of outputs per license type;
- Plot an interactive stacked bar plot showing the proportion of outputs of each type issued under a given license type.